Common Problems in Image Classification and Object Detection Training

Machine learning for image classification and object detection sounds straightforward, until you're neck-deep in debugging misclassifications or training stalls. In this post, we'll unpack some real-world problems we've faced while working on the image classification of solar inverters for asset compliance auditing and our strategies to tackle them.
Convolutional Neural Networks (CNNs) are an impressive tool, but they aren’t magic. They’ve got quirks that can lead to subtle bugs or costly inefficiencies if not accounted for during training. Here's a closer look at some of these issues and how we dealt with them.
The Rotation Invariance Problem
Rotating an image of a solar inverter slightly can throw a classifier off its game. CNNs don’t natively handle rotations well, as they learn patterns specific to the orientation seen during training. Our first solution was the obvious one: augmentation. But adding all possible rotations was computationally expensive and introduced diminishing returns.
Instead, we built an augmentation pipeline that rotated images to a canonical orientation before passing them to the classifier. This way, the classifier could focus on what it does best, detecting features, without being thrown off by rotations.
The Overlapping Class Problem
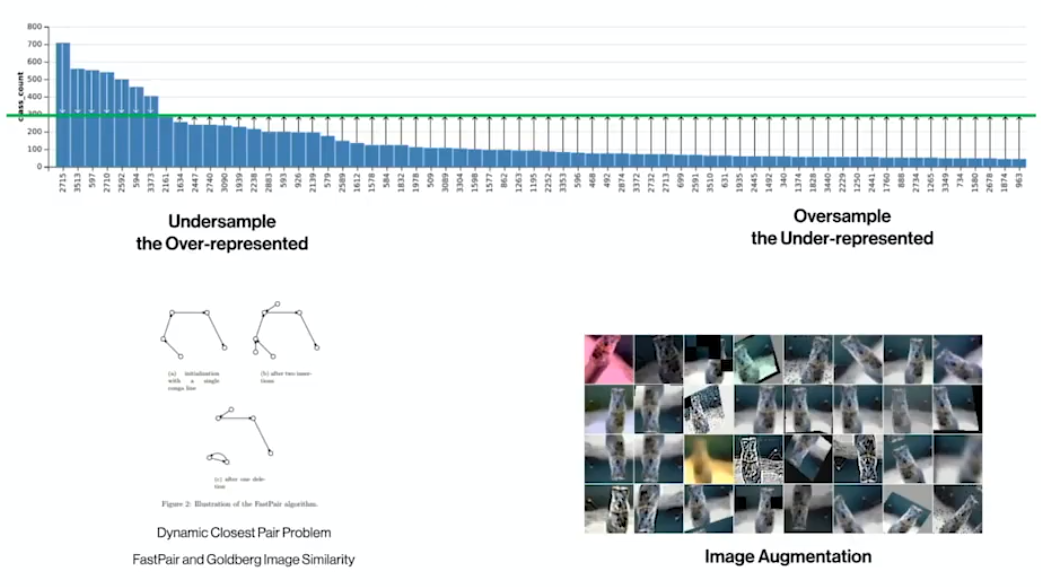
Are two visually identical inverters always the same model? Not when government compliance regulations step in. This issue arises when classes overlap visually to the point that even a human would struggle to distinguish them. Our classifier often struggled with such ambiguity, leading to misclassifications that were technically correct in appearance but incorrect by regulatory standards.
To address this, we used a dual strategy of oversampling underrepresented classes and undersampling overrepresented ones. For oversampling, we augmented underrepresented classes with transformations such as rotations, scaling, and brightness adjustments. This artificially increased the diversity of these classes in the training dataset, improving the model's ability to recognize rare variants.
For undersampling overrepresented classes, we turned to a combination of the Goldberg image similarity metric and the FastPair algorithm. By applying these tools, we could identify and eliminate redundant images within the same class, effectively reducing the dominance of overrepresented classes in the dataset. The Goldberg metric quantifies similarity between images, while FastPair efficiently computes the dynamic closest pair problem, identifying which images to remove without excessive computational overhead.
This balanced the class distribution and forced the classifier to learn finer details that distinguish visually similar but semantically different classes. The result was a more equitable training set and improved performance across all classes, especially those prone to overlap.
The Unary Classification Problem
Not every image fed into our pipeline contains a solar inverter, some might not even contain anything useful. Early on, we manually labeled our training set to include only relevant images. But let’s face it, humans make mistakes, and this process doesn’t scale.
Our solution was to implement a unary classifier, trained specifically to detect whether an image contained a solar inverter at all. We based this on the work of Chalapathy et al. in their paper "Learning Deep Features for One-Class Classification", which uses a loss function designed around compactness and descriptiveness.
These two principles, compactness and descriptiveness, are key to the unary classification challenge. Compactness ensures that embeddings of "in-class" samples, like solar inverters, are tightly grouped in the feature space, while descriptiveness ensures these embeddings remain distinct from all "out-of-class" samples, representing the vast and unpredictable variety of everything else.
This approach aligns conceptually with loss functions like center loss or triplet loss. Center loss minimizes intra-class variance by pulling features closer to their class center, and triplet loss separates embeddings based on anchor, positive, and negative sample relationships. Similarly, compactness penalizes embeddings that are too spread out, while descriptiveness works to maximize separation between the target class and the infinite set of "non-inverter" samples.
Unary classification is fundamentally different from binary classification. Binary classifiers have the advantage of defined, balanced categories, allowing clear decision boundaries to be learned. In unary classification, we deal with an inherently asymmetrical scenario: one well-defined target class against an undefined "everything else." This imbalance makes traditional binary loss functions unsuitable, as they can't account for the boundless diversity of irrelevant data in the background class.
Training such a model requires overcoming additional challenges. Noise in the dataset, such as mislabeled examples or edge cases, can confuse the classifier. Additionally, the dataset needs to be representative of the class's full variation to ensure robustness. To address this, we augmented our training dataset with diverse samples of solar inverters captured under varying conditions, ensuring the model learned the distinguishing features that generalized well.
By filtering irrelevant data early in the pipeline, the unary classifier acts as a gatekeeper, passing only relevant images downstream. This saves computational resources and enhances the efficiency of later tasks, such as fine-grained classification and object detection. It’s an essential component of building robust and scalable machine learning pipelines for real-world applications.
File Systems Aren't Just a Storage Problem
Training large models on massive datasets is already a headache without slow file systems or flaky VPN connections piling on. Early on, we wasted hours restarting training jobs because of these bottlenecks. Enter Mothra: our content-addressed filesystem designed for high-speed access and stability.
Mothra hashes all inputs using multihash and stores them on S3, with a local disk cache to handle frequent reads. This improved stability and reduced training time significantly. By cutting out our reliance on NFS or EFS and their VPN dependencies, we streamlined our workflow and slashed costs.
Why It Matters
These solutions aren't just clever hacks; they're investments in reliability. When you're building a system for something as critical as asset compliance auditing, every misclassification can lead to compliance violations or wasted man-hours. And let's not forget: AI systems that fail in high-stakes scenarios don’t just disappoint, they erode trust in the technology itself.
We'll continue exploring ways to improve model robustness and training efficiency, including diving deeper into augmentation strategies, transfer learning, and domain adaptation in future efforts.
For the full presentation, watch the YOW! Data 2019 talk:
