
Declarative Stateless Migrations in Databases
10 min read

Ever since we read Domen Kožar's thoughts on how Nix and NixOS is a superior configuration management system because it features:
- Declarative Semantics
- Stateless
- Deterministic (pure)
- Avoids dependency hell
- Idempotent
- Atomic/Transactional
- Reversible or Rollbacks
We've been thinking about how to apply the Nix philosophy to live database migrations. (Specifically relational SQL databases.)
Our motivation is due to problems faced by current database migration solutions. Most solutions do not feature " desired-state" configuration. Instead the migrations are coded in imperative manner, coding the explicit actions to take in order to migrate schema or data. The migration can fail which means they are not-deterministic. In the instance of failure, they may not be able to be safely retried which means they are neither idempotent nor atomic/transactional. Once your state is corrupted due a partially failed migration, it is no longer possible to reverse. These are problems that are going to arise for any developer orchestrating large stateful systems.
Configuring an operating system is not fundamentally different from configuring a database. Is it possible for us to work out a theory that achieves those 4 properties (declarative, stateless, atomic, and reversible) for database migrations? Let's see!
Databases support 2 types of languages: Data Definition Languages (DDL) and Data Manipulation Languages (DML). During a migration both DDLs and DMLs can be used. During live operations, generally only DMLs are used, however there's nothing stopping one from using DDLs during live operations. DDL and DML can be used together, if you add a new column using DDL, you may also need to add new data using DML.
Any solution needs to achieve all of the properties for both DDLs and DMLs.
Declarative
SQL is somewhat declarative. But there are parts that are not declarative. For
example a standard INSERT is a very imperative statement. In order to achieve
the first property, we need to restrict ourselves to using declarative
statements. A declarative statement is one that defines the end state that we
want the database to be at. DML operations that are declarative include UPSERT
and DELETE. Pretty much all DDL operations are declarative.
Stateless
To achieve the stateless property, we first need to understand what we mean by stateless configuration management. In the Nix and NixOS article, the author demonstrates that existing configuration management takes in the current state of the filesystem as a side-effectful input to the package build function.
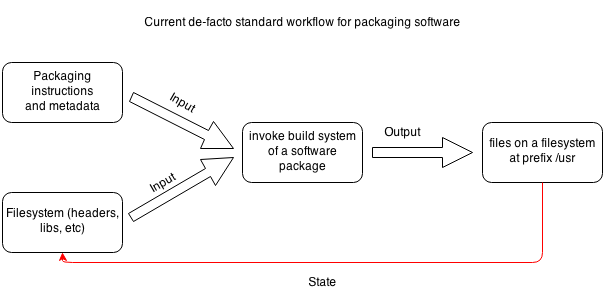
This makes the package build function impure. A pure function is a function where the return value is only determined by its input values, without observable side effects. The package build function inside Nix is a stateless function, as there are no observable side effects. All inputs are explicitly declared and passed into the build process.
Simply put, stateless functions are deterministic.
We can see that SQL operations do not work as pure functions. They are side effectful, as the return value of the operation depends on the mutable state of the database, and the operation itself changes the state of the database. You could imagine that a SQL operation is a closure that is closed over the state of the database. If the state of the database was immutable, then the operation would be pure, but it isn't.
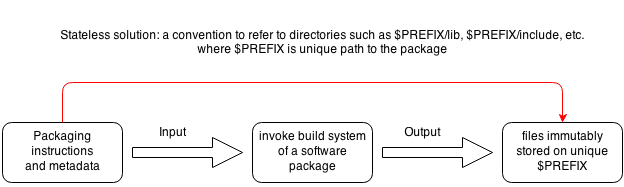
Nix and NixOS fixes this problem by forcing you to pass all required dependencies into package build function. (An optimisation phase can find out shared dependencies and establish hardlinks, which saves space.) A package build function never has to rely on the existing filesystem state. Although the saving of the build output does in fact change the filesystem state. This mutation doesn't affect subsequent executions of the build function, and doesn't affect the return value.
In order to acquire stateless SQL operations, each operation must either take in the entire database state as a parameter, or be considered a closure with a free variable that is filled by the database state, and return a new database state without changing the previous closed over database state.
The only kinds of databases that support such kind of SQL operations are the rare functional append-only databases like Datomic (sometimes called purely functional databases). However I do not know whether Datomic even supports append-only DDLs (schema changes).
It may be possible simulate a functional append-only database in normal SQL by
creating unique database prefixes for each change. But this is totally
impractical as the database structure is not shared. What we really need is some
sort of
persistent data structures
or
structural immutability
or structure
sharing functionality
.
Thinking outside the box, an infrastructural solution is to shift your perspective on the single of source of truth to a [temporal log structured database][https://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying] instead , and just consider your relational stores as a current-database representation/lens/view. This prevents the need to think about migrations as changing the source of truth, but instead simply changing the lens structure in which you perceive the data.
Idempotency
In general we can't achieve the stateless feature that Nix possesses in mainstream SQL databases. But we can achieve idempotent property in a slightly less expressive way. What we need is idempotent DDLs and DMLs in our migrations. Idempotence is the property that rerunning an operation should result in the same behaviour. [Idempotency is a necessity for fault tolerance][http://research.microsoft.com/apps/pubs/?id=173885].
Idempotent DMLs rely not just on the availability of UPSERT and DELETE but
also the
exact semantics equality/inequality.
For example the UPSERT command needs to branch between an UPDATE or
INSERT. How does it decide whether the current state is conflicting with your
UPSERT? What does it mean for 2 records to be conflicting? Most SQL systems do
this through the existence of some sort of unique key. The uniqueness of that
key defines the semantics of inequality, and thus signals to the database that
there is a row conflict, which converts the UPSERT command into a UPDATE
command. Another variation on UPSERT is the INSERT IGNORE or
ON CONFLICT DO NOTHING, this basically branches between INSERT or a no-op.
An interesting solution from service oriented architecture, is the usage of
combining a unique hash for any given transaction
{transaction_details, hash_id}, for example
Stripe allows idempotent API charge calls.
Idempotent DDLs are even more challenging, as very few databases support this natively. So it requires a bit of hacking. Refer to these resources for more:
- http://www.depesz.com/2008/06/18/conditional-ddl/
- http://haacked.com/archive/2006/07/05/bulletproofsqlchangescriptsusinginformation_schemaviews.aspx/
- http://johnbender.us/2013/11/04/a-better-sql/
- http://johnbender.us/2014/04/07/presentation-differential-semantics/
- http://blog.geekq.net/2010/08/11/add-column-safely-mysql/
The advantage of idempotency is that it offers more safer migrations that can deal with migration failure, so theoretically you can just rerun all the migrations all the time.
The previous sentence needs to be considered carefully. It is only true, when you consider all mutations of the database as a migration in schema or data. If you consider that migrations scripts to be a subset of all mutations that have occurred on your database, then it is not safe to simply rerun all of your idempotent mutation scripts, because the current state of your data may no longer match your desired state specified in your migrations. You may end up affecting state that you didn't want changed.
In practice, if you are able to keep track all mutations as migrations, you can rerun migrations from the beginning, if not, then you always migrate forward and never backward. This implies a need to keep track of the the "version" your database is at, and to know where your migrations sit in the "version heritage tree" of your database.
Atomic/Transactional
Nix also makes its changes in an atomic manner. All package builds live in their own unique prefix, so changes do not affect other packages. Furthermore the packages are only symlinked to global configuration at the end after everything is built. That means if a package build is only partially completed because the network failed, or because the power failed, or you cancelled, the package will not have been symlinked to the global configuration, and you can run a garbage cleaning operation to remove any non-symlinked packages.
During a migration, our DDLs and DMLs must also be encapsulated in transactions. This is hard requirement. Not all databases support transactional DDLs (MySQL doesn't). Implicit commits are not legal here!
When any aspect of a migration fails, the entire migration should be rolled back. This is also important in the presence of syntax errors. You don't want a syntax error in one of your SQL statements to cause a partial operation.
Reversible or Rollbacks
Nix is also both reversible (revertible) and roll-backable. There's a difference between "reversing/reverting a migration" and "rolling back a migration". This difference is best demonstrated by the way git works. Reversing is a forward compensating action. Whereas rolling-back is a matter of rewriting history.
In NixOS every execution of system configuration is saved as a generation. You can easily rollback to a previous generation. Packages that exist in previous generations are not deleted unless you first garbage collect the old generations. It's also possible to make changes to your configuration that semantically "reverses" a previous configuration in a forward compensating manner.
While reversing a migration is a matter of writing a forward compensating migration, rolling-back migrations is a more difficult proposition for mainstream SQL databases, as it is not practical to hold all previous generations of your data. This problem is related to the stateless problem discussed above. Functional append-only databases provide a solution. However these databases would also need to be able to apply append-only logic to both DDL and DML.
Another problem here is coupling a DDL and DML migration together. In NoSQL databases, where the schema is just in the application logic, migrating DDL is just a matter of changing source code, but there's no obvious place to put your DML changes. The answer is to also couple it with your application deployment, something that is present in the same versioned commit that added your DDL changes.
For traditional SQL databases, there is a common theme to the alternatives
proposed for statelessness and " rollbackability". It's basically some sort of
log structured archiving, and point-in-time recovery. [PostgreSQL offers
"continuous
archiving".][http://www.postgresql.org/docs/devel/static/continuous-archiving.html].
This feature is also called
"Continuous Data Protection".
Of
course it's easier to implement, if your
database is already a log.
This doesn't strictly give you properties of statelessness, but it does make
migrations more safer.
Schema Evolution and Other Related Ideas
There is on-going database research to deal with these kinds of problems. The literature calls this "schema evolution". It's not just the evolution of the schema, but the underlying data as well. Futhering the idea is the ability of not just replaying data, or recovering data, but manipulating the past data as well, just like [rewriting git history][https://git-scm.com/book/en/v2/git-tools-rewriting-history].
In programming language theory, there's a related concept called "modular extensibility". While for high-availability systems, hot-code reloading or zero-downtime deployments faces the exact same problems of declarativeness, statelessnes, atomic transactions and reversibility or "rollbackability". In game development, there's a similar issue of knowing how a change in a particular entity's property affects the game world's balance. This was investigated using graph theory and Neo4j.
Also checkout these slides talking about using git as a database.